
PostgreSQL large object storage for Odoo

The default storage in Odoo
The previous default storage method in OpenERP 7 for attachments was far from optimal : files were encoded into base64 and stored in a bytea PostgreSQL type, which is not much more than a text type... In Odoo 8 this is even worse : files are stored by default on the filesystem, in a directory called "filestore". So that the PostgreSQL dumps now are incomplete, and you cannot replicate or backup efficiently. To be able to "backup" your odoo instance, the backup procedure from the web interface now produces a ".dump" file, which is just a zip containing the real pg dump, and the filestore. Odoo 8 is globally awesome but this specific point is a real bad one. Some old wizard, somewhere, in the ancient times, must have publicly declared that it's faster to serve files directly from the filesystem. Most of the time this is eventually wrong. Since that time people tend to obey to this belief, at the price of sacrificing consistent and replicable storage. Or maybe we missed something in the Odoo online Saas hosting requirements.
PostgreSQL large objects
For a long time PostgreSQL has been supporting large objects. You can access the documentation of this feature here: http://www.postgresql.org/docs/9.4/static/largeobjects.html. As a summary, large objects (or blobs) are just binary files stored in a separate system table, split into b-tree indexed chunks and can be accessed with a convenient file-like API. The good thing is a database can be dumped without large objects, so you don't have to be afraid of the growing size of the database : even if the full dump is 10GB, you can easily dump it without the large objects just by using: pg_dump --schema=public.
As an example, on our own Odoo instance, the full dump is currently larger than 100MB while the dump without the blobs is below 20MB.
An Odoo module that stores attachments as large objects
The ir_attachment object is quite easy to subclass, so we implemented a large object storage for ir_attachments in our attachment_large_object module:
https://gitlab.anybox.cloud/odoo-addons/common/advanced_attachment
Installing the module
You can install it very easily, as any other module. Here is an example of a buildout configuration for Odoo 8 :
[buildout]
parts = odoo
versions = versions
find-links = http://download.gna.org/pychart/
[odoo]
recipe = anybox.recipe.openerp:server
version = git http://github.com/anybox/odoo.git odoo 8.0
addons = hg https://bitbucket.org/anybox/advanced_attachment/ advanced_attachment 8.0
options.load_language = fr_FR
options.language = fr_FR
eggs = anybox.testing.openerp
anybox.recipe.openerp
nose
pytest
PyPDF
openerp_scripts = nosetests=nosetests openerp-log-level=WARNING command-line-options=-d
[static-analysis]
recipe = zc.recipe.egg
eggs = pyflakes
flake8
anybox.recipe.openerp
[versions]
zc.buildout = 2.2.5
If you're news to this type of buildout configuration for Odoo, you should read the documentation of the recipe.
Activate the large object storage
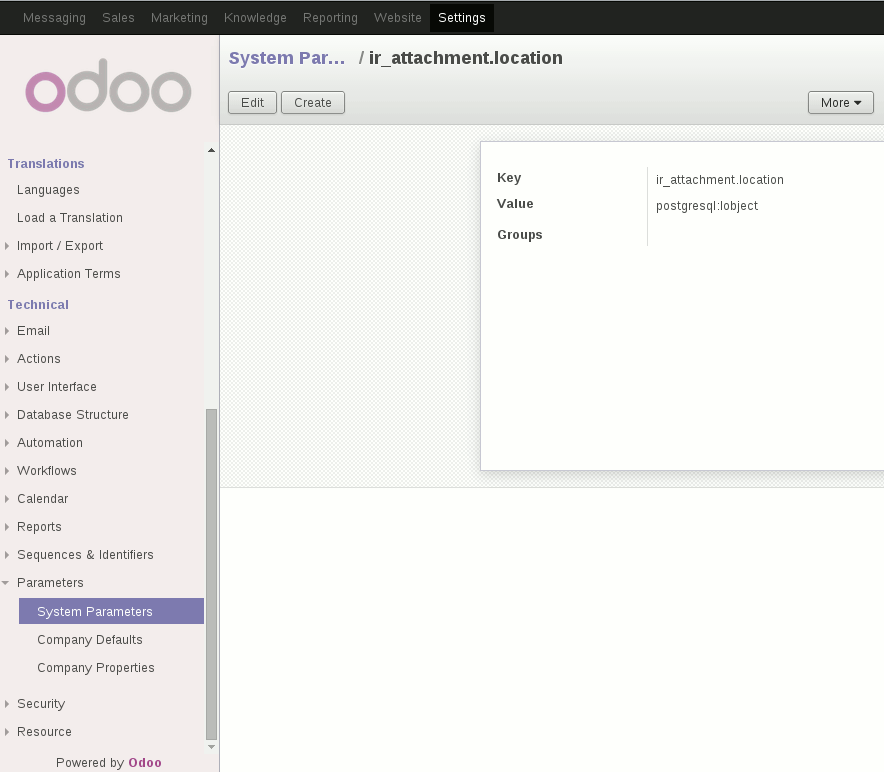
After installation, the only thing to do is to add or modify the ir_attachment.location parameter in the system configuration menu, so that it's value is: postgresql:lobject
Migrating your attachments from legacy storage
After enabling the largeobject storage, all your new files will be stored as blobs, while the old ones will be kept untouched. If you want to use the new blob storage for all your previous attachments, you'll have to migrate them. Migration in this case actually just consists in reading and rewriting the same file.
If you're using the Odoo buildout recipe, you can use the generated upgrade.py upgrade script to write your upgrade procedure. Below is an example that does the following :
- It installs the attachment_large_object module
- It creates the needed ir.config_parameter to activate the new storage
- It migrates old attachments to the new storage
- It updates all the module (equivalent to running -u all )
This kind of upgrade script is extremely useful during deployments, to achieve reliable upgrade procedures. You can keep your script growing with new upgrades, as long as you correctly handle the version number of the database. This versionning number is specific to the buildout recipe, you can see the current version in the system parameter menu : buildout.db_version: 3. The example script below updates the version number twice because the install_module method commits and closes the cursor in the middle. In case something's wrong during the second phase and you have to relaunch the upgrade, the 1st one is not replayed.
# upgrade.py
def run(session, logger):
cr, uid = session.cr, session.uid
if session.db_version < '1':
# migrate filestore-based attachments to blob-based attachments
session.db_version = '1'
logger.info("Installing additional modules...")
session.update_modules_list()
session.install_modules(['attachment_large_object',])
session.open(cr.dbname)
cr, uid = session.cr, session.uid
if session.db_version < '2':
logger.info("Migrating attachments...")
# first enable the advanced attachment
session.registry('ir.config_parameter').set_param(
cr, uid, 'ir_attachment.location', 'postgresql:lobject')
# now migrate attachments
atts = session.registry('ir.attachment')
cr.execute('select id from ir_attachment '
'where datas_big is not NULL '
'or store_fname is not NULL')
for att_id in cr.fetchall():
att = atts.browse(cr, uid, att_id)
att.datas = att.datas.encode('utf-8')
att.db_datas = False
att.datas_big = False
logger.info("Migrated attachment %s", att_id)
session.db_version = '2'
cr.commit()
logger.info("Updating all modules...")
session.update_modules(['all'])
After writing your upgrade script, you just have to run :
./bin/upgrade_odoo -d DATABASEHappy replicating and dumping
After enabling this module you'll be able to replicate your whole databases to provide high-availability hosting like we do, without needing to replicate the filesystem.
You'll also be able to dump the db as usual with:
pg_dump -Fc -O -f DATABASE.dump DATABASEor dump without the large objects :
pg_dump -Fc -O --schema=public -f DATABASE.dump DATABASEWhat about performance?
On a simple test on an Odoo CMS image like this one, there is no performance penalty.
ab -n 1000 -c 20 http://127.0.0.1:8069/website/image/ir.attachment/82_6d7b07b/datasActually there is no difference at all between the three storages (db, file, lobject) : we measured the same rate of 112 req/s on a common laptop.
Anyway when serving files on a web site, you typically set up a caching server such as Varnish, so even if the first loading of the file is very long, the database is almost never accessed again : the file is served from the cache.
What about database size?
We recently migrated one of our customers using a lot of reports to this storage and here is the result:
Full dump before migration: 1.78GB
$ pg_dump -Fc -O -f snesup_2014-12-19T22:46.dump snesup-rw-r--r-- 1 snesup openerp 1,78G déc. 19 21:53 snesup_2014-12-19T22:46.dumpFull dump after migration: 1.37GB
$ pg_dump -Fc -O -f snesup_2014-12-19T22:46-after-lo-update.dump snesup-rw-r--r-- 1 snesup openerp 1,37G déc. 19 23:01 snesup_2014-12-19T22:46-after-lo-update.dumpDump without attachments : 29MB
$ pg_dump -Fc -O -f snesup_2014-12-19T22:46-after-lo-update-public.dump snesup --schema=public-rw-r--r-- 1 snesup openerp 29M déc. 19 23:02 snesup_2014-12-19T22:46-after-lo-update-public.dump